4 Rekomendasi Algoritma Machine Learning untuk Klasifikasi

Untuk dapat menemukan pola dibalik suatu dataset agar bisa lebih bermanfaat lagi, diperlukan sebuah algoritma machine learning. Machine learning sendiri membahas tentang bagaimana cara mesin dapat belajar sendiri sehingga mesin tersebut dapat melakukan tugas tertentu tanpa terprogram secara eksplisit. Tidak seperti AI yang dapat meniru kemampuan manusia dalam merespon suatu sistem, machine learning justru mampu membuat algoritmanya sendiri untuk proses belajar. Konsep kerja machine learning dalam menggunakan algoritma yang telah terprogram adalah dengan menerima dan menganalisis data inputan untuk kemudian dapat memprediksi nilai keluaran atau output.
Berdasarkan algoritma-algoritma tersebut terdiri dari tiga tipe algoritma diantaranya Supervised Learning, Unsupervised Learning, dan Reinforcement Learning. Pada kesempatan kali ini, kami akan membahas tentang empat rekomendasi algoritma machine learning yang digunakan untuk pengklasifikasian. Jadi, jangan beranjak dan baca artikel DQLab sampai selesai, ya!
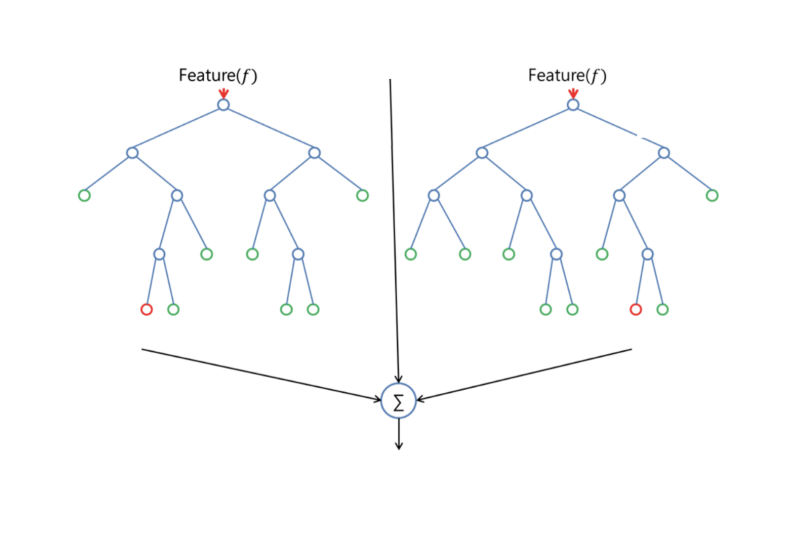
1. Random Forest
Random forest merupakan salah satu algoritma yang digunakan untuk pengklasifikasian dataset dalam jumlah besar. Klasifikasi random forest dilakukan melalui penggabungan tree dengan melakukan training dataset yang kamu miliki. Selain itu, algoritma random forest menggunakan algoritma decision tree untuk melakukan proses seleksi. Dimana tree atau pohon yang dibangun dibagi secara rekursif dari data pada kelas yang sama. Proses klasifikasi pada random forest berawal dari memecah data sampel yang ada dalam decision tree secara acak. Setelah pohon terbentuk,maka akan dilakukan voting pada setiap kelas dari data sampel. Kemudian, mengkombinasikan vote dari setiap kelas kemudian diambil vote yang paling banyak.Dengan menggunakan random forest pada klasifikasi data maka, akan menghasilkan vote yang paling baik. Pada saat proses klasifikasi selesai dilakukan, inisialisasi dilakukan dengan sebanyak data berdasarkan nilai akurasinya. Keuntungan penggunaan random forest yaitu mampu mengklasifikasi data yang memiliki atribut yang tidak lengkap,dapat digunakan untuk klasifikasi dan regresi akan tetapi tidak terlalu bagus untuk regresi, lebih cocok untuk pengklasifikasian data serta dapat digunakan untuk menangani data sampel yang banyak.
Baca juga : 3 Jenis Algoritma Machine Learning yang Dapat Digunakan di Dunia Perbankan
2. Naive Bayes
Naive bayes merupakan metode pengklasifikasian paling populer digunakan dengan tingkat keakuratan yang baik. Banyak penelitian tentang pengklasifikasian yang telah dilakukan dengan menggunakan algoritma ini. Berbeda dengan metode pengklasifikasian dengan logistic regression ordinal maupun nominal, pada algoritma naive bayes pengklasifikasian tidak membutuhkan adanya pemodelan maupun uji statistik. Naive bayes merupakan metode pengklasifikasian berdasarkan probabilitas sederhana dan dirancang agar dapat dipergunakan dengan asumsi antar variabel penjelas saling bebas (independen). Pada algoritma ini pembelajaran lebih ditekankan pada pengestimasian probabilitas. Keuntungan algoritma naive bayes adalah tingkat nilai error yang didapat lebih rendah ketika dataset berjumlah besar, selain itu akurasi naive bayes dan kecepatannya lebih tinggi pada saat diaplikasikan ke dalam dataset yang jumlahnya lebih besar.
3. Support Vector Machine
SVM (Support Vector Machine) adalah algoritma klasifikasi yang memiliki kinerja yang bagus, tingkat keakuratan yang dinilai cukup tinggi untuk pengklasifikasian data, dan error rate yang dihasilkan minimum. Adapun keuntungan dari algoritma SVM adalah dapat menentukan hyperplane atau pemisah dengan memilih bidang yang memiliki optimal margin maka generalisasi pada SVM dapat terjaga dengan sendirinya, tingkat generalisasi pada SVM tidak dipengaruhi oleh jumlah data latih , dengan menentukan parameter soft margin, noise dapat dikontrol pada kesalahan klasifikasi sehingga proses pelatihan menjadi jauh lebih ketat.
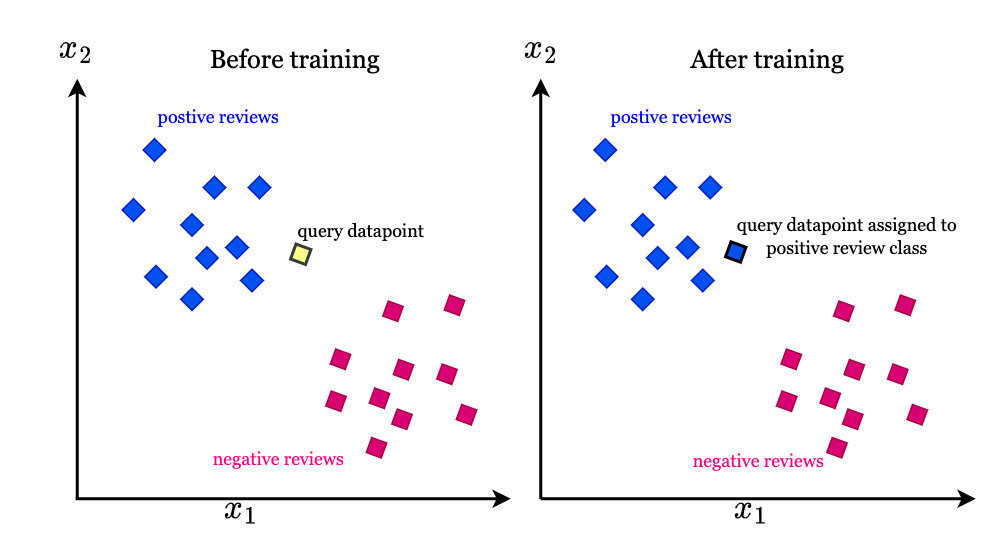
4. KNN
Algoritma KNN atau sering disebut K-Nearest Neighbor merupakan algoritma yang melakukan klasifikasi berdasarkan kedekatan jarak suatu data dengan data yang lain. Dekat atau jauh suatu jarak dihitung berdasarkan jarak Euclidean. KNN merupakan salah satu algoritma non parametrik yang digunakan dalam pengklasifikasian. Selain naive bayes, algoritma KNN juga menjadi algoritma pengklasifikasian yang terkenal dengan tingkat keakuratan yang baik. Keuntungan dari algoritma KNN adalah sangat nonlinear, lebih mudah dipahami dan diimplementasikan karena kita cukup mendefinisikan fungsi untuk menghitung jarak antar-instance, menghitung jarak x dengan semua instance lainnya berdasarkan fungsi tersebut dan menentukan kelas x sebagai kelas yang paling banyak muncul di k-instance.
Baca juga : Belajar Data Science: Pahami Penggunaan Machine Learning pada Python
5. Intip Modul DQLab Tentang Algoritma Machine Learning Disini, Yuk!
Dengan modul dan materi yang update, belajar python menggunakan bahasa menjadi lebih mudah dan terstruktur bersama DQLab. Karena terdiri dari modul-modul up-to-date dan sesuai dengan penerapan industri yang disusun oleh mentor-mentor berpengalaman dibidangnya dari berbagai unicorn, dan perusahaan besar seperti Tokopedia, DANA, Jabar Digital dan masih banyak lagi. Yuk, belajar terstruktur dan lebih interaktif cukup dengan Sign up sekarang di DQLab.id atau klik button dibawah ini untuk nikmati pengalaman belajar yang seru dan menyenangkan!
Penulis: Rian Tineges
Editor: Annissa Widya Davita
Mulai Karier
sebagai Praktisi
Data Bersama
DQLab
Daftar sekarang dan ambil langkah
pertamamu untuk mengenal
Data Science.


Daftar Gratis & Mulai Belajar
Mulai perjalanan karier datamu bersama DQLab
Sudah punya akun? Kamu bisa Sign in disini