Belajar Data Science di DQLab: Data Cleansing Tahap Awal Data Science Studi Kasus Telekomunikasi

Project Data ini dikembangkan oleh Ira Irawaty, member DQLab dengan project yang diberikan oleh Data Mentor DQLab, Anton Suhartono, Data Scientist Telkom Indonesia.
Belajar Data Science untuk membangun Portofolio Data dengan melakukan data cleansing, tahap awal data science menggunakan studi kasus telekomunikasi
Dalam studi kasus kali ini, Irene Irawaty menjabarkan tahapan data cleansing telco yang ingin mengurangi perpindahan jumlah pelanggan (churn) berdasarkan data pada Juni 2020. Cleansing dilakukan menggunakan Python dan Pandas dan dibagi menjadi 5 tahapan yaitu:
1. Memfilter ID Customer dengan format tertentu, serta membuang data yang mengandung duplikasi. Jumlah row data ketika pertama kali di load ada sebanyak 7113 rows. Setelah melewati filter dengan Regex terdapat 7006 rows. Kemudian di cek duplikasi dari ID Customer, setiap data duplicat akan dihapus sehingga tersisa 6993 rows.
2. Menghapus Missing Values pada kolom Churn dan setelah kita tangani dengan cara penghapusan terdapat 43 rows yang berhasil dihapus.
3. Mengisi Missing Values dengan nilai tertentu dan nilai median dari kolom tertentu sehingga terbukti sudah tidak ada missing values lagi pada setiap kolom pada dataset.
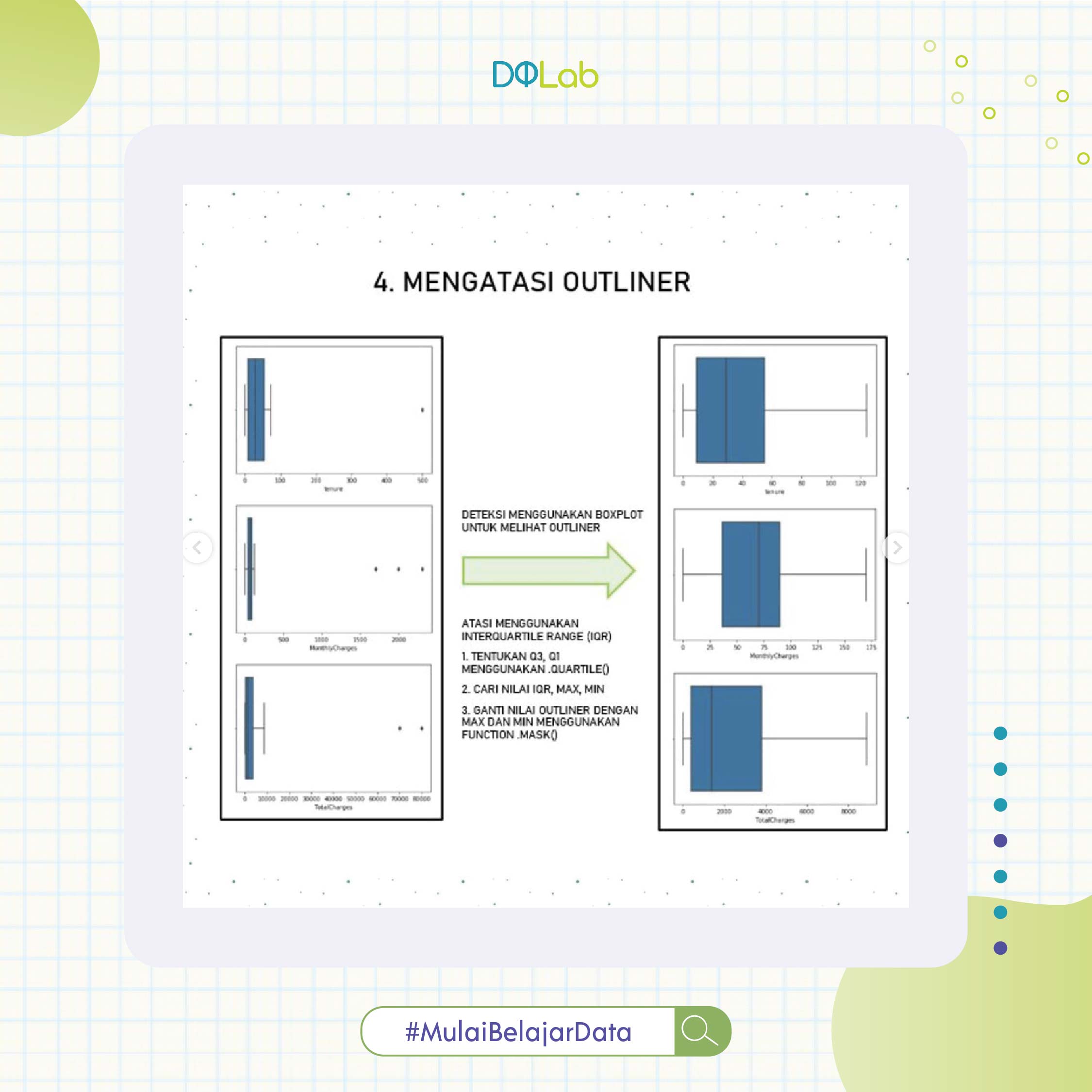
4. Mengatasi Outliner pada kolom 'tenure','MonthlyCharges' & 'TotalCharges' karna berdasarkan boxplot, terdapat titik titik yang berada jauh dari gambar boxplotnya. Kemudian nilai outlier tersebut ditangani dengan cara merubah nilainya ke nilai Maximum & Minimum dari interquartile range (IQR). Setelah di tangani, pada persebaran data nya terlihat sudah tidak ada lagi nilai yang outlier pada boxplot.
5. Standarisasi Variable pada kolom Gender yang bisa di standarkan nilainya menjadi (Female, Male). Kolom Dependents di standarkan nilainya menjadi (Yes, No). Kolom Churn, di standarkan nilainya menjadi (Yes, No). Sehingga terlihat bahwa seluruh variable sudah menjadi terstandar dengan baik untuk unique value nya.
--Irene Irawaty, Data Scientist Intern Telkom Indonesia--




Bangun Portofolio Datamu!

Kamu bisa membangun portofolio datamu dengan belajar data science di DQLab. Untuk kamu yang ingin siap berkarir jadi Data Analyst, Data Scientist, dan Data Engineer, persiapkan diri kamu dengan tepat sekarang. Tidak ada kata terlambat untuk belajar. Yuk #MulaiBelajarData di DQLab. Kamu bisa:
- Menerapkan teknik mengolah data kotor, hasilkan visualisasi data dan model prediksi dengan studi kasus Retail dan Finansial
- Dapatkan sesi konsultasi langsung dengan praktisi data lewat data mentoring
- Bangun portofolio data langsung dari praktisi data Industri
- Akses Forum DQLab untuk berdiskusi.
Mulai Karier
sebagai Praktisi
Data Bersama
DQLab
Daftar sekarang dan ambil langkah
pertamamu untuk mengenal
Data Science.


Daftar Gratis & Mulai Belajar
Mulai perjalanan karier datamu bersama DQLab
Sudah punya akun? Kamu bisa Sign in disini