Metode Pengolahan Data: Yuk Pelajari Natural Language Processing untuk Mempermudah Proses Pengolahan Data Text!

Digital Transformation adalah proses mengubah data atau informasi dari satu format ke format lainnya dengan teknologi digital. Proses ini mengubah format sistem sumber menjadi format yang diperlukan sesuai tujuan yang ingin dicapai. Proses Ini tidak hanya melibatkan konversi dokumen tetapi juga melibatkan konversi program dari satu bahasa komputer ke bahasa lain untuk mendukung dan membantu suatu program berjalan pada platform yang berbeda. Dalam praktiknya, transformasi data melibatkan program khusus yang mampu membaca bahasa bawaan data, membaca bahasa di suatu program, dan mentransformasi data tersebut. proses data transformasi dibagi menjadi dua fase yaitu data mapping dan code generation. Data mapping merupakan proses untuk menangkap semua transformasi yang terjadi dalam proses data transformation sedangkan code generation adalah proses pembuatan program transformasi yang akan dijalankan pada sistem komputer.
Tujuan digital transformation adalah mengolah data menjadi data dengan format tertentu. Metode yang digunakan dalam proses pengolahan data sangat bervariasi. Secara umum, semua jenis data dapat diolah sesuai dengan tujuan yang diinginkan. Jenis data yang banyak digunakan saat ini adalah data berbentuk text atau string. Salah satu metode yang dapat digunakan untuk mengolah data text adalah natural language processing atau biasa disingkat dengan NLP. NLP adalah sub bidang ilmu komputer dan artificial intelligence yang berkaitan dengan interaksi antara komputer dan bahasa manusia. Metode ini digunakan untuk menerapkan algoritma machine learning ke teks dan ucapan. Misalnya, kita dapat menggunakan NLP untuk membuat sistem seperti pengenalan ucapan, ringkasan dokumen, mesin terjemahan, mendeteksi spam, mesin koreksi text otomatis, dan sebagainya. Salah satu penerapan NLP pada kehidupan sehari-hari adalah deteksi suara pada smartphone. Dengan metode ini, smartphone dapat memahami dan mencatat secara otomatis kata-kata yang diucapkan oleh seseorang. Lalu apa saja yang dapat kita lakukan dengan metode natural language process ini? Kali ini DQLab akan menjelaskan sekaligus mempraktekkan dasar-dasar pengolahan data text menggunakan metode NLP dengan bahasa pemrograman python. Yuk berlatih bersama!
1. Sentence Tokenization dan Word Tokenization
Sentence tokenization atau dikenal juga dengan sentence segmentation merupakan proses pembagian data text tertulis menjadi kalimat komponennya. Cara kerja proses ini adalah memisahkan kalimat berdasarkan tanda baca. Hal pertama yang harus kita lakukan adalah memanggil library yang akan digunakan. Kali ini kita akan menggunakan library NLKT. Sete;ah itu tulis kalimat yang akan kita pisahkan. Agar lebih jelas, Kamu bisa melihat script berikut
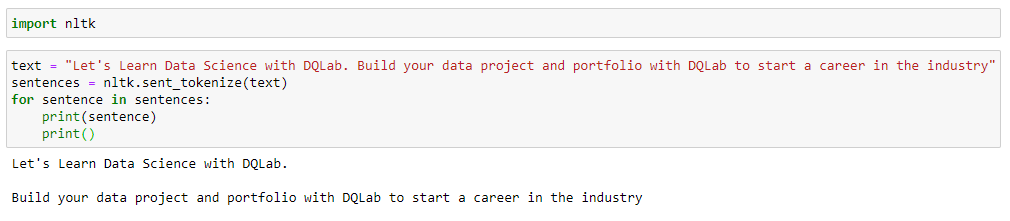
Kalimat awal pada variabel text adalah "Let's Learn Data Science with DQLab. Build your data project and portfolio with DQLab to start a career in the industry" Setelah proses sentence tokenization selesai, kalimat tersebut dipisahkan dengan tanda baca titik dan terurai menjadi dua kalimat yang terpisah. Mudah, kan? Yuk lanjut ke proses berikutnya!
Word tokenization atau dikenal juga dengan word segmentation adalah proses pemisahan kalimat menjadi kata-kata penyusunnya. Biasanya, karakter yang digunakan untuk memisahkan kata-kata penyusun sebuah kalimat adalah white space atau spasi. Nah kali ini, kita akan mencoba menguraikan beberapa kata penyusun kalimat dengan pemisah spasi. Mudah kok, kalian cukup menyalin script dibawah ini.

Dalam proses pemisahan kata, kita menggunakan fungsi nltk.word_tokenize yang kita tuliskan di bawah script sentence tokenization. Nah, setelah proses word tokenization selesai, kata-kata penyusun kalimat pada variabel sentences sudah diuraikan.
Baca Juga: Teknik Pengolahan Data: Yuk Pelajari Teknik Pengolahan Data yang Tepat Sesuai Tujuan Penelitianmu!
2. Stop Words
Stop words adalah kata-kata yang disaring sebelum atau setelah teks selesai diproses. Tidak semua kata-kata yang telah diproses akan kita butuhkan. Terkadang kata-kata yang tidak bermakna tersebut dapat menjadi noise. Oleh karena itu kita harus menghapus kata-kata yang tidak relevan ini. Pada artikel kali ini kita menggunakan contoh kalimat berbahasa inggris sehingga kata umum yang akan kita hapus menggunakan pada proses stop words adalah kata-kata umum berbahasa inggris seperti "and", "the", "a", dan lain sebagainya. Kita tidak perlu mencatat semua kata tersebut karena library NLTK memiliki daftar stopword standar yang merujuk ke kata yang paling umum. Pertama kita harus mendowload daftar tersebut dengan menuliskan script nltk.download ("stopwords") di lembar kerja python. Setelah itu, kita dapat menggunakan package stopwords dari nltk.corpus untuk menghapus kata sesuai daftar yang telah kita unduh.
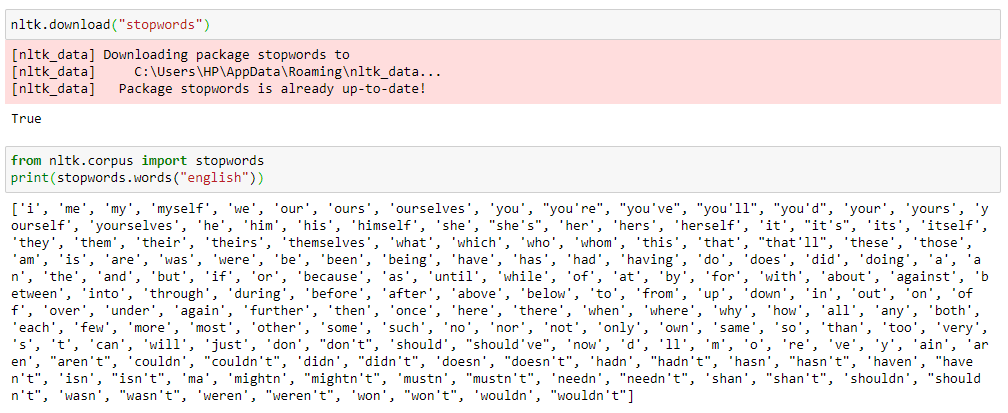
Daftar kata di atas merupakan beberapa kala paling umum yang ada di daftar library NKTL. Selanjutnya kita cukup menyalin script berikut untuk menghapus kata-kata yang tidak kita butuhkan. Tapi ingat ya, kata yang akan dihapus adalah kata-kata yang ada di daftar yang sudah kita download sebelumnya.

Setelah proses stop words selesai, kata "build", "your", "and", "with", "to", "a", "in", dan "the" pada kalimat "Build your data project and portfolio with DQLab to start a career in the industry" sudah terhapus.
3. Regex
Perhatikan output script berikut ini

Apakah menurutmu ada yang aneh dari output di atas? Yap! tanda baca titik tetap dibaca sebagai sebuah karakter yang terpisah. Padahal, karakter titik tersebut hanya sebagai tanda baca dan tidak memiliki arti yang signifikan dalam proses pengolahan data. Tanda baca tersebut dapat menjadi noise dan mempengaruhi hasil pengolahan data sehingga kita harus menghapus karakter tersebut. Proses penghapusan tanda baca ini tidak sulit. Kita bisa menggunakan RegEx. Regex, or regexp adalah urutan karakter yang menentukan pola pencarian. RegEx merupakan singkatan dari Regular Expression atau dalam bahasa indonesia disebut ekspresi reguler. Ekspresi reguler menggunakan karakter garis miring terbalik ('') untuk menunjukkan bentuk khusus. Kita bisa menggunakan modul re dan menggunakan fungsi re.sub untuk menghapus suatu karakter.

digital transformation adalah salah satu komponen dalam data science. Saat kita belajar digital transformation, tidak afdol rasanya jika kita tidak belajar data science. Saat ini data science merupakan bidang ilmu penting yang banyak dicari karena dapat digunakan di semua bidang. Tidak ada syarat khusus untuk belajar data science karena data science dapat dipelajari oleh siapapun dengan background pendidikan apapun.
Baca Juga: Teknik Pengolahan Data: Yuk Pelajari Teknik Pengolahan Data yang Tepat Sesuai Tujuan Penelitianmu!
4. Mulai Belajar Data Science Sekarang!
Tidak memiliki background IT? Jangan khawatir, kamu tetap bisa menguasai Ilmu Data Science untuk siap berkarir di revolusi industri 4.0. Bangun proyek dan portofolio datamu bersama DQLab untuk mulai berkarir di industi! Sign up sekarang untuk #MulaiBelajarData di DQLab!
Simak informasi di bawah ini untuk mengakses gratis module "Introduction to Data Science":
Buat Akun Gratis dengan Signup di DQLab.id/signup
Akses module Introduction to Data Science
Selesaikan modulenya, dapatkan sertifikat & reward menarik dari DQLab
Subscribe DQLab.id untuk Akses Semua Module Premium!
Penulis: Galuh Nurvinda Kurniawati
Editor: Annissa Widya Davita
Mulai Karier
sebagai Praktisi
Data Bersama
DQLab
Daftar sekarang dan ambil langkah
pertamamu untuk mengenal
Data Science.


Daftar Gratis & Mulai Belajar
Mulai perjalanan karier datamu bersama DQLab
Sudah punya akun? Kamu bisa Sign in disini