Algoritma Support Vector Machine Bagi Data Science

Data science bekerja dengan beragam algoritma untuk menyelesaikan permasalahan. Secara umum algoritma tersebut dibedakan menjadi dua berdasarkan cara kerjanya, yaitu supervised dan unsupervised learning. Garis besar perbedaannya adalah ada atau tidaknya data yang perlu dipelajari oleh algoritma untuk membentuk suatu model. Ini pun tergantung dari ketersediaan data sehingga pemilihan algoritma sangat penting dalam data science.
Algoritma data science yang cukup populer dalam supervised learning terutama untuk permasalahan klasifikasi adalah algoritma support vector machine. Apa sebenarnya algoritma tersebut? Bagaimana pula cara kerjanya? Nah, bagi kalian yang pemula dan sedang mendalami teori yang berkaitan dengan algoritma, yuk simak pembahasan mudah berikut ini!
1. Definisi Algoritma Support Vector Machine
Support Vector Machine adalah salah satu metode dalam supervised learning yang biasanya digunakan untuk klasifikasi ataupun regresi. Dalam pemodelan klasifikasi, support vector machine memiliki konsep yang lebih matang serta jelas secara matematis dibandingkan dengan teknik klasifikasi lainnya. Support vector machine juga dapat mengatasi masalah klasifikasi dan regresi dengan metode linear maupun non linear.
Algoritma Support Vector Machine digunakan untuk mencari hyperplane terbaik dalam ruang N-dimensi yang secara jelas mengklasifikasikan titik data. Hyperplane adalah sebuah fungsi yang digunakan sebagai pemisah antar kelas yang satu dengan yang lain. Fungsi ini digunakan untuk mengklasifikasikan di dalam ruang kelas dimensi yang lebih tinggi. Dalam bentuk 2 dimensi, fungsi yang digunakan untuk mengklasifikasikan antar kelas disebut dengan line whereas. Sedangkan fungsi yang digunakan untuk mengklasifikasikan antar kelas dalam bentuk 3 dimensi disebut plane similarly.
2. Ilustrasi 1: Terdapat 2 Hyperplane
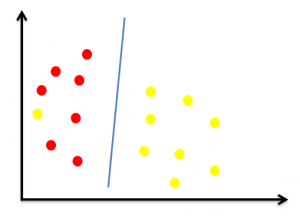
Disini kita akan mencoba mengidentifikasi hyperplane terbaik untuk mengklasifikasikan titik merah dan kuning. Perhatikan gambar berikut.
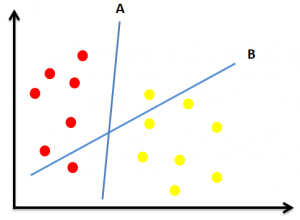
Seperti yang kita lihat pada gambar di atas, ada 2 garis yang merupakan hyperplane (A dan B). Manakah dari dua garis tersebut yang dapat dikatakan sebagai hyperplane terbaik? Aturan pertama adalah pilih hyperplane yang dapat mengklasifikasikan dua kelas dengan lebih akurat. Jika begitu, maka dapat kita simpulkan bahwa hyperplane A adalah yang terbaik.
Baca juga : Memahami Keunggulan dan Manfaat Data Science dalam Dunia Bisnis
3. Ilustrasi 2: Terdapat 3 Hyperplane
Selanjutnya perhatikan contoh di bawah ini.
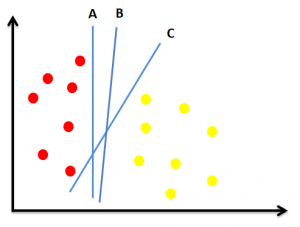
Ketiga hyperplane di atas (A, B, dan C) sama-sama membagi titik merah dan kuning dengan akurat. Nah, bagaimana cara menentukan hyperplane terbaik untuk kasus ini? Untuk memutuskan mana hyperplane terbaik, kita dapat mengukur margin-nya, yaitu jarak antara hyperplane dengan titik terdekat dari tiap kelas. Perhatikan ilustrasi di bawah ini.
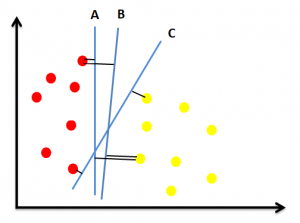
Untuk menentukan mana hyperplane yang terbaik, pilih hyperplane yang tidak terlalu dekat dengan titik terdekat di masing-masing kelas atau dengan kata lain memaksimalkan jarak hyperplane dengan titik terdekat di tiap kelas. Jika kita perhatikan, hyperplane A terlalu dekat dengan titik merah terdekat sedangkan cukup jauh dengan titik kuning terdekat. Begitu juga dengan hyperplane C, jaraknya dengan titik merah dan kuning terdekat cukup dekat.
Hyperplane B pada gambar di atas, memiliki jarak yang tidak terlalu dekat ke dua titik (merah dan kuning) terdekat, sehingga dapat dikatakan bahwa hyperplane B adalah yang terbaik. Intinya, untuk menentukan hyperplane terbaik, jangan ada titik di salah satu kelas yang berada sangat dekat dengan hyperplane, sementara titik terdekat pada kelas lainnya berada sangat jauh dari hyperplane.
4. Ilustrasi 3: Terdapat Outlier pada Data
Perhatikan ilustrasi di bawah ini.
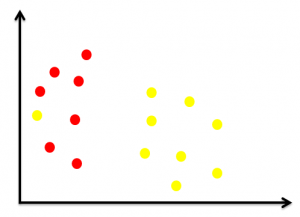
Algoritma Support Vector Machine memiliki fitur untuk mengabaikan outlier dan menemukan hyperplane terbaik yang memiliki margin maksimum. Algoritma SVM bekerja sangat baik dalam menangani outlier atau pencilan. Hyperplane terbaiknya akan tampak seperti gambar di bawah ini.
Baca juga : 3 Contoh Penerapan Data Science yang Sangat Berguna di Dunia Perindustrian
5. Keuntungan Penggunaan Algoritma Support Vector Machine
Berikut sejumlah keuntungan menggunakan algoritma SVM dalam mengklasifikasikan data.
Algoritma support vector machine membantu apabila tidak memiliki banyak ide tentang data.
Dapat digunakan untuk data yang tidak berdistribusi teratur.
Memiliki teknik yang sangat sesuai untuk masalah yang kompleks.
Tidak mengalami kondisi overfitting dan bekerja dengan baik untuk data yang memiliki outlier.
Memiliki tingkat akurasi yang lebih baik dibandingkan model lainnya.
Memiliki kemampuan untuk menormalkan data.
Dalam ilmu data science, permasalahan yang ada tidak hanya berkaitan dengan klasifikasi saja. Tentunya masih banyak lainnya seperti sistem rekomendasi, analisis regresi, analisis prediksi, dan masing-masing permasalahan membutuhkan algoritma yang berbeda pula. Nah bagaimana membedakan algoritma dan fungsinya? Kalian tidak perlu khawatir, DQLab hadir untuk membantu kalian agar semakin paham dengan kegunaan setiap algoritma. DQLab memiliki modul pembelajaran yang akan membimbing kalian dari materi dasar hingga penggunaannya di industri yang berbeda.
Yuk, segera daftarkan diri kalian dengan Sign Up untuk mengasah kemampuan menggunakan beragam algoritma data science dalam menyelesaikan kasus-kasus di kehidupan nyata!
Penulis : Dita Feby
Editor : Annissa Widya
Mulai Karier
sebagai Praktisi
Data Bersama
DQLab
Daftar sekarang dan ambil langkah
pertamamu untuk mengenal
Data Science.


Daftar Gratis & Mulai Belajar
Mulai perjalanan karier datamu bersama DQLab
Sudah punya akun? Kamu bisa Sign in disini