Macam-Macam Algoritma Klasifikasi Machine Learning yang Penting Untuk Diketahui

Saat ini, perusahaan berteknologi besar maupun kecil, semua bersaing untuk mewujudkan teknologi paling canggih. Kamu pasti pernah mendengar atau membaca bacaan yang membahas tentang perusahaan berteknologi berskala besar. Hal tersebut pasti tidak jauh dengan istilah yang digunakan pada teknologi seperti, Data Science, AI (Artificial Intelligence), Machine Learning, Deep Learning, hingga Natural Language Processing.
Dalam dunia Data Science, kita dapat membuat model Machine Learning menggunakan beberapa bahasa di antaranya adalah Python. Python saat ini masih menjadi bahasa yang sangat digemari oleh banyak pihak. Hasil belajar Machine Learning dengan python banyak sekali menghasilkan tools yang membantu dalam kemudahan interaksi bahkan mempersingkat kerja manusia.
Tipe tipe algoritma pada Machine Learning terdiri dari Unsupervised Learning, Supervised Learning dan Semi Supervised Learning. Seperti yang pernah dibahas di artikel lainnya, Machine Learning tanpa data maka tidak akan bisa bekerja. Oleh sebab itu, hal yang pertama kali perlu disiapkan adalah data. Untuk menghasilkan pola atau suatu kesimpulan yang diinginkan, algoritma pada Machine Learning menghasilkan suatu model yang didasari sebuah data. Setelah mengetahui garis besar tipe algoritma-algoritma Machine learning secara umum, berikut ini sedikit penjelasan terkait contoh-contoh dari algoritma yang telah disebutkan di atas!
1. Hierarchical Clustering
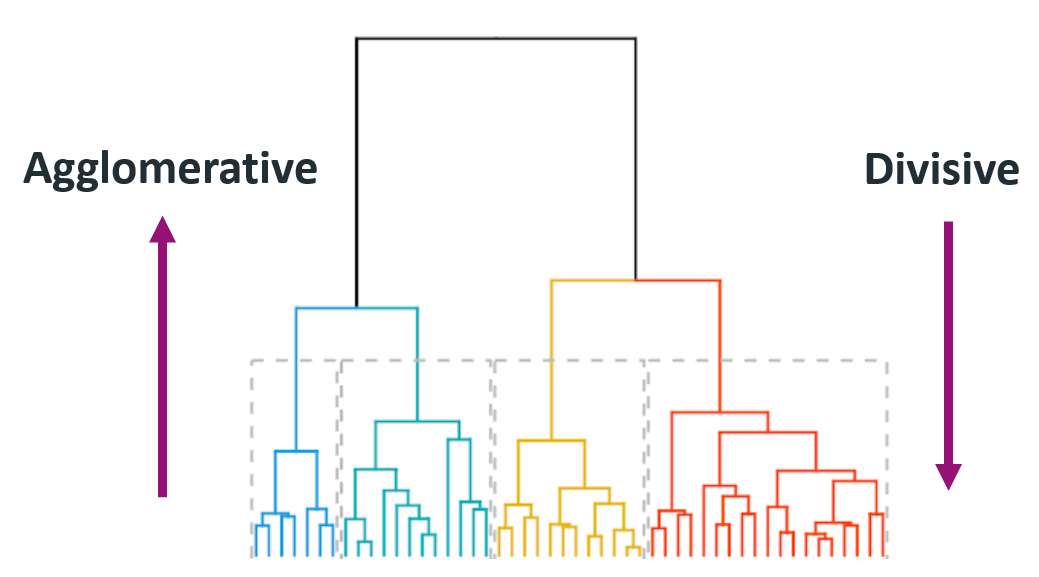
Hierarchical Clustering adalah teknik clustering dengan algoritma Machine Learning yang membentuk hirarki atau berdasarkan tingkatan tertentu sehingga menyerupai struktur pohon. Dengan demikian proses pengelompokannya dilakukan secara bertingkat atau bertahap. Biasanya, metode ini digunakan pada data yang jumlahnya tidak terlalu banyak dan jumlah cluster yang akan dibentuk belum diketahui.
Secara prinsip, Hierarchical Clustering ini akan melakukan clustering secara berjenjang berdasarkan kemiripan tiap data. Sehingga pada akhirnya, pada ujung hierarki akan terbentuk cluster-cluster yang karakteristiknya berbeda satu sama lain, dan objek di satu cluster yang sama memiliki kemiripan satu sama lain.
Di dalam metode hirarki, terdapat dua jenis strategi pengelompokan yaitu Agglomerative dan Divisive. Agglomerative Clustering (metode penggabungan) adalah strategi pengelompokan hirarki yang dimulai dengan setiap objek dalam satu cluster yang terpisah kemudian membentuk cluster yang semakin membesar. Jadi, banyaknya cluster awal adalah sama dengan banyaknya objek. Sedangkan Divisive Clustering (metode pembagian) adalah strategi pengelompokan hirarki yang dimulai dari semua objek dikelompokkan menjadi cluster tunggal kemudian dipisah sampai setiap objek berada dalam cluster yang terpisah.
Baca juga : 3 Jenis Algoritma Machine Learning yang Dapat Digunakan di Dunia Perbankan
2. K-Means Clustering
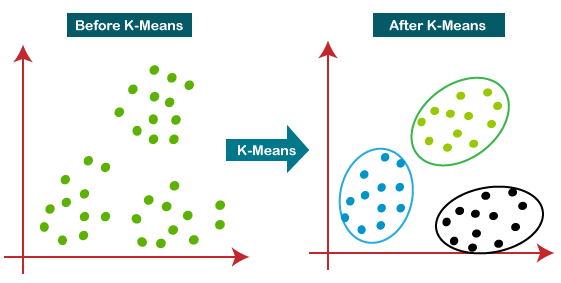
Seperti namanya, algoritma ini biasa digunakan untuk kasus clustering. K-means Clustering adalah salah satu contoh algoritma Unsupervised Machine Learning yang paling sederhana dan populer. Metode K-Means Clustering berusaha mengelompokkan data yang ada ke dalam beberapa kelompok, dimana data dalam satu kelompok mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik yang berbeda dengan data yang ada di dalam kelompok yang lain.
Cara kerja algoritma ini mula-mula adalah dengan membentuk sejumlah k titik, yang disebut dengan centroid (dimana nilai k merepresentasikan jumlah cluster). Kemudian titik-titik data (data points) yang ada akan membentuk cluster dengan centroid terdekat darinya. Otomatis, titik pusat (centroid) akan berubah seiring dengan pertambahan anggota tiap cluster-nya (yang mana adalah data points tadi). Oleh karena itu, tiap-tiap cluster yang telah terbentuk akan mencari titik centroid barunya. Proses ini terus menerus dilakukan hingga diperoleh kondisi konvergensi, contohnya jika posisi centroid sudah tidak berubah.
Terdapat dua jenis data clustering yang sering dipergunakan dalam proses pengelompokan data yaitu Hierarchical dan Non-Hierarchical, dan K-Means merupakan salah satu metode data clustering non-hierarchical atau Partitional Clustering.
3. Decision Trees
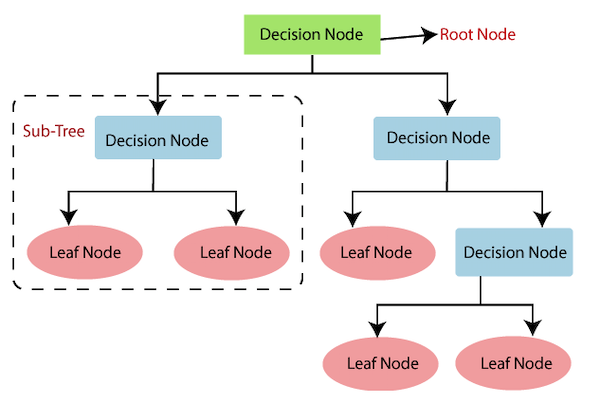
Decision Tree adalah salah satu metode klasifikasi yang paling populer, karena mudah untuk diinterpretasi oleh manusia. Decision Tree adalah model prediksi menggunakan struktur pohon atau struktur berhirarki. Algoritma Machine Learning jenis ini melakukan tugasnya dengan menggunakan konsep struktur flowchart bercabang menggunakan decision rules atau aturan-aturan keputusan yang dibuat oleh desainernya.
Pada dasarnya, Decision Tree dimulai dengan satu node atau simpul. Kemudian, node tersebut bercabang untuk menyatakan pilihan-pilihan yang ada. Selanjutnya, setiap cabang tersebut akan memiliki cabang-cabang baru. Maka dari itu, metode ini disebut "tree" karena bentuknya menyerupai pohon yang memiliki banyak cabang. Mengutip dari Venngage, Decision Tree memiliki tiga elemen di dalamnya, yaitu:
Root node (akar), Tujuan akhir atau keputusan besar yang ingin diambil.
Branches (ranting), Berbagai pilihan tindakan.
Leaf node (daun), Kemungkinan hasil atas setiap tindakan.
4. Random Forest
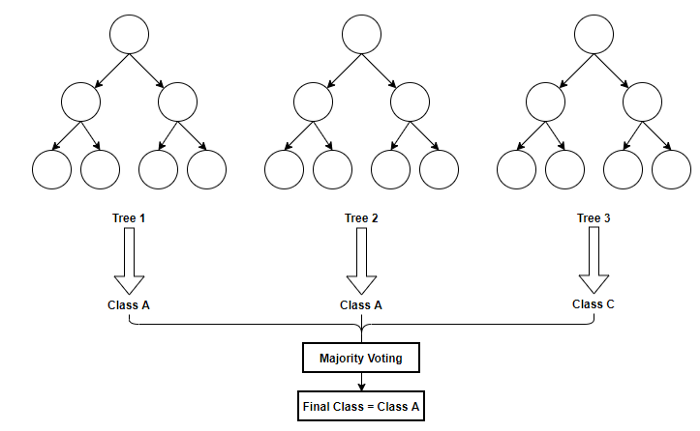
Dalam Machine Learning kita akan sering mendengar tentang metode Random Forest yang digunakan untuk menyelesaikan permasalahan. Metode Random Forest merupakan salah satu metode dalam Decision Tree. Random Forest adalah kombinasi dari masing-masing tree yang baik kemudian dikombinasikan ke dalam satu model. Random Forest bergantung pada sebuah nilai vector random dengan distribusi yang sama pada semua pohon yang masing masing Decision Tree memiliki kedalaman yang maksimal.
Oleh karena itu, prinsip dasar random forest mirip dengan Decision Tree. Masing-masing Decision Tree akan menghasilkan output yang bisa saja berbeda-beda. Nah, Random Forest ini akan melakukan voting untuk menentukan hasil mayoritas dari semua Decision Tree. Sederhananya, Random Forest akan memberikan output berupa mayoritas hasil dari semua Decision Tree.
Baca juga : Machine Learning vs Deep Learning Korelasi AI, Machine Learning dan Deep Learning
5. Terapkan Contoh-Contoh dari Algoritma Machine Learning Bersama DQLab
Jika kamu ingin tahu lebih mengenai tipe algoritma-algoritma Machine Learning serta ingin belajar secara langsung, DQLab adalah solusi yang tepat. Caranya mudah, kamu bisa memulainya dengan membuat akun GRATIS di DQLab.id/signup. Nikmati pengalaman belajar Data Science yang menarik bersama DQLab yang seru dan menyenangkan dengan live code editor yang simple. Selain itu, kamu juga bisa mengerjakan free module Introduction to Data Science with R dan Introduction to Data Science with Python untuk menguji kemampuan Data Science kamu. Yuk persiapkan dirimu untuk berkarir sebagai praktisi data yang kompeten!
Penulis : Salsabila Miftah Rezkia
Editor : Annissa Widya Davita
Mulai Karier
sebagai Praktisi
Data Bersama
DQLab
Daftar sekarang dan ambil langkah
pertamamu untuk mengenal
Data Science.


Daftar Gratis & Mulai Belajar
Mulai perjalanan karier datamu bersama DQLab
Sudah punya akun? Kamu bisa Sign in disini